In this 2-week project, I aimed to try something completely different from what I practiced in the previous project. Instead of the text data, there were 6M rows of numbers. Rather than munging the data for purely personal interest, I built predictive models that can potentially address a business solution for mobile fraud detection.
This was a collaborative project done by Maria Gayà Fiol and myself. The data we selected was a simulated mobile money transaction log available on the Kaggle website, generated by PaySim based on a sample of real transactions extracted from one month of financial logs from a mobile money service implemented in an African country. (Reference: E. A. Lopez-Rojas , A. Elmir, and S. Axelsson. “PaySim: A financial mobile money simulator for fraud detection”. In: The 28th European Modeling and Simulation Symposium-EMSS, Larnaca, Cyprus. 2016).
Our goal was to understand the features closely related to fraudulent profit by exploratory data analysis and make good predictions on the unseen data based on our findings. To enhance prediction performance, we implemented different machine learning algorithms including logistic regression, random forest, XGBoost, and neural network.
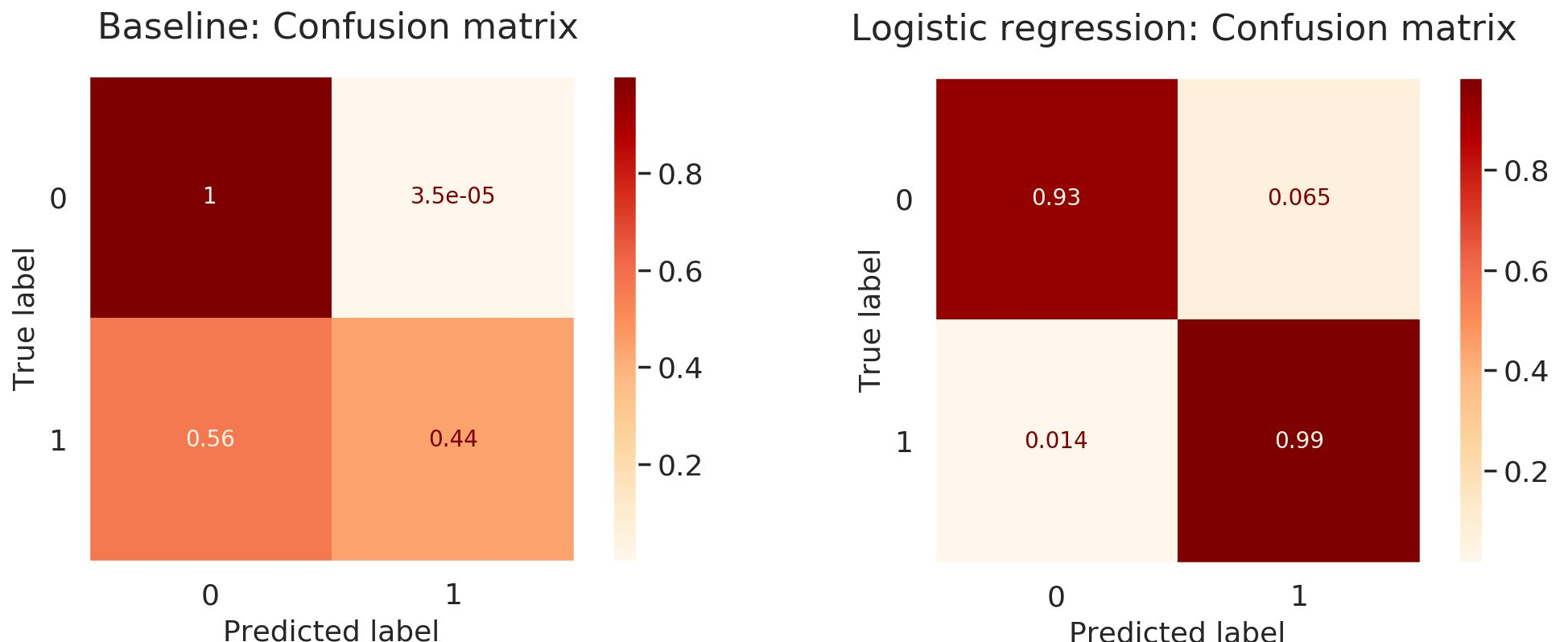
The main challenge of this data was to predict its highly unbalanced binary targets. The population of real fraudulent activity among the entire records was only 0.1%. Therefore, it was crucial to detect all possibly-fraud transactions, lowering the false-negative cases(=fail to detect real frauds; FN) even if it means to involve some false positives(=falsely asserting a case as a fraud when it’s not; FP).
The benefit of this synthetic data is that analysts like us could conduct fraud analytics overcoming the lack of public access to private records. However, its simplicity in feature attributes easily led us to the overfitting of algorithms. As our observation, implementing the logistic regression was enough to detect 99% of the fraud transactions maintaining a relatively low FP rate(6.5%) when introduced ‘class_weight’ hyperparameter to compensate for the imbalance present in the dataset.
Check this repository where my part of the data analysis and modeling is available.